python 語法筆記(不斷更新)
- python,numpy,pandas数据处理之小技巧
- 排序: iterable為放置需要排序的陣列或是list(可迭代),reverse則是看要不要反過來排序,預設是false
sorted( iterable ,reverse= False)
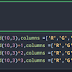
- 排序:(np.sort) 排序。可以依照raw or column來排序
np.sort( iterable ,axis =0 )
list array 問題
- list ,ndarray 小數轉int:
np.around(list or ndarray)
- list與array:
list : [object]
/ 一維 : 不等於 list ,要轉成list ,使用 : list( array )
array: np開頭
\ 多維 : 要降成一維 ,使用 : .ravel()
- list(str) : 把str轉成list:str裡面的每個字元都被當成'字串':
str= 'hello'
list(str)
- list轉array
np.asarray(list)
- 一維array轉2維:
np.reshape(1-Darray, (幾x幾) )
- List 新增:
a=[1,2,3,4]
b=[5,6,7,8]
c = a+b #直接用 + 即可
a.append(b[0]) #用b[0]
print c
[1, 2, 3, 4, 5, 6, 7, 8]
print a
[1, 2, 3, 4, 5]
- array新增(一維): np.append
- aa= np.array([1,2,3,4])
- bb= np.array([5,6,7,8])
cc1= aa+bb #在array裡若直接用 + 則是進行array內運算
cc2= np.append(aa,bb) #需使用append ,一維是橫向往後增加
print cc1
[ 6 8 10 12]
print cc2
[1 2 3 4 5 6 7 8]
(二維): np.append
aa2= np.reshape(aa,(1,4))
bb2= np.reshape(bb,(1,4))
cc2= np.append(aa2,bb2,axis=0) # 二維 可指定axis,0則是往下堆疊
cc3= np.append(aa2,bb2,axis=1) # 二維 可指定axis,1則是往橫向堆疊
cc4= np.append(aa2,bb2) # 若不指定axis 則轉為一維的array
print cc2
[[1 2 3 4]
[5 6 7 8]]
[5 6 7 8]]
print cc3
[[1 2 3 4 5 6 7 8]]
print cc4
[1 2 3 4 5 6 7 8]
- List 移除 插入
lis =[1,2,3,4,5]
lis.remove(lis[0]) #移除第一個
lis.insert(0,'error') . # 在第0的位置 插入error字串
- List replace:
原list =[w.replace( '原本的字符','要改成的字符') for w in 原list] # w是遍歷用的
- 字串拆解和結合(list)---結合: .join 把原本list裡的char 依照串接的字符變成新的字串
新str= '要串接的字符'.join([原char]) # '要串接的字符'比如 :',' '.' 之類
- 字串拆解和結合(list)---拆解: .split() 把原本的字串拆解並存成list
新list= 字串.split('依照該字符做拆解') # 依照提供的特徵:字符 做拆解 並轉為list裡面的index
- list刪除:
del list[index] #直接指定要刪除的位置index
- ndarray 裡的值如果要修改:
1D array: ndarray.itemset( 位置, 要改成的值 )
2D array: ndarray.itemset( (位置,位置) 要改成的值 )
- pandas 轉array ,list
# 轉array:df[column].as_matrix() # 轉list:df[column].values.tolist()- 取值的位置(index):
a= [10,20,30,40,50]
a.index(10)
回傳 0
- input() 與raw_input():
input("想顯示的東西") 之後回傳只能keyin 數字
raw_input("想顯示的東西") 。之後回傳能keyin 數字與字串
- 把滑鼠複製的data轉成dataframe:
import pandas as pd
y= pd.read_clipboard()
y
存讀檔
1. npy讀寫效率最高,但最佔硬碟空間,比如np.load(), np.save();
2. csv其次,比如pd.Dataframe.to_csv(),pd.load_csv();
3. txt讀寫,當然也可以很快,但是需要频繁的split,對格式規範的數據比较麻烦;
4. 至於簡單的excel和word,可以用xlrd,xlwt來操作
- 一般存檔:
a= [1,2,3,4]
with open ('filename' , 'w' ) as f:
pickle.dump( a , f )
- 一般讀檔: pickle沒有副檔名
pickle.load( open('filename', 'r') )
- pandas存pickle檔:
dataframe.to_pickle('檔名.pickle')
- pandas讀pickle檔:
pd.read_pickle('檔名.pickle')
- numpy 存檔:(自動存成npy檔):
np.save( '檔名', 要存的list 或 array )
- numpy 讀檔:
np.load( ' 檔名.npy' )
- text讀檔: 讀出來格式是str 字符串
with open(txtfile)as f:
Text_str = f.read()
os操作:遍歷,新增:
1. 新建文件夹:
if not os.path.isdir(path_out):
os.makedirs(path_out)
2. 遍歷所有文件和子文件夹: # a: 路徑 b:資料夾 c:總文件
for a, b, filenames in os.walk(path_data):
for filename in filenames:
3.只遍歷當前文件,不包含子文件夹:
for a, b, filenames in os.walk(path_data):
for filename in filenames:
if a == path_data:
確認nan 布林
- 確認dataframe是否為null:
pd.isnull(object)
- 確認array是否為null:
np.nan(array)
- 設定nan:
np.nan
- 用 np.isfinite() 判斷布林值
x=np.array([1,2,np.nan,4,5])
np.isfinite(x)
- 再利用上面的判斷 ,忽略nan值
import numpy as np
import matplotlib.pyplot as plt
time=np.array([1,2,3,4,5])
f1=np.array([1,2,np.nan,4,5])
#忽略nan ,因為丟進[]裡面所以假使是2d array也會被轉成一維
plt.plot(time[np.isfinite(f1)], f1[np.isfinite(f1)])
plt.show()
- numpy.ndarray 的nan填補:
example = np.where(np.isnan(example), 0, example)
example = np.where(np.isnan(example), 0, example)
- dataframe 的nan填補:
可以用example.fillna() 也可以用example.replace(a, b)
- 線性迴歸:
from scipy import stats
# 斜率 。 截距 。 變異係數 。相關係數 。 標準誤差
slope, intercept, r_value, p_value, std_err = stats.linregress(wait,what)
r_value**2
- 畫圖的colormap設定 與 c的隨機配色
plt.scatter(x,y, s=20, c=np.random.rand(100),marker='o', cmap=plt.cm.jet, alpha= 0.5 )
plt.scatter(x[u],y[u], s=10, c=(np.random.rand(),np.random.rand(),np.random.rand()),
marker='o', alpha= 0.3 )
- 要把list裡面的數字都round(取小數四捨五入):
lis= [55.45,15.5,33.9]
ss= [round(i,0) for i in lis] #小數點後0位 四捨五入
| 這封郵件來自 Evernote。Evernote 是您專屬的工作空間,免費下載 Evernote |