macOS: Install OpenCV 3 and Python 2.7
開頭先引用下大陸網友針對安裝python+opencv所下的註解吧:
"如何正确安装OpenCV历来是一个堪称玄学的问题,在成功安装OpenCV的道路上经历了种种艰辛,这真的是我最恶心的一次安装经历"
認同,因為我也花了四天的時間在安裝。由於本身系統下之前就已經安裝過不同版本的python,再加上用的是notebook做分析開發。所以一直沒有正視過標準IDE+opencv。 藉著公司專案告一段落,就開始思考因為notebook的檔案格式是.ipynb很明顯地跟.py檔是不同,也意味著我在分析上用notebook可以很方便快速,但是如果當我要導入到Arduino或其他系統端要應用時就不可能了。 簡單來說就是該面對的還是要面對....
上網找了Pycharm做IDE,基本上設定相關沒太大問題,只是需要習慣下操作模式。(畫圖,import,debug,查看變數 等等 )
接下來要測試影像處理,之前在notebook上有 import cv2 ,原以為已經安裝成功了,雖然當時心裡想說 怎一下下就安裝好了??想當初在xcode上要安裝也是花了老半天。 果然在跑pycharm時候就報錯了:
The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or
Carbon support. If you are on Ubuntu or Debian, install libgtk2.0-dev and
pkg-config, then re-run cmake or configure script
一開始以為是少安裝了GTK之類的,上google上找看到大多數碰到這類error的好像都是ubuntu的系統,所以就開始到處亂安裝@@ 結果當然不行
後來仔細看看報錯原因,似乎是說明function沒有被implement,也就是說我安裝不完全。
想想也對,之前載opencv都好幾百mb然後安裝都要時間,我當初在terminal上用 pip install opencvㄧ下下就好 這差異也太大。
於是上網找了下資訊,最後找到有正解的教學:
http://www.pyimagesearch.com/2016/11/28/macos-install-opencv-3-and-python-2-7/
那到底難在哪呢?
前面提到,因為我系統本身就安裝過很多版本的python 有2也有3 後來安裝opencv2,3 也透過anaconda安裝過 也從官網下載過, 所以可以說是系統雜 亂。再加上教學上提到需要增加虛擬環境來安裝,雖然不是必要 ,再加上我覺得麻煩所以沒完全按照他的教學步驟,導致後來一直安裝不成功。。。
最後想開了,因為系統亂灌,最安全的方式,就是需要在乾淨的環境下安裝才能確保沒有其他因素造成安裝出問題,其實最大因素就是出在路徑啦!!!
所以依照上面網址教學一步步安裝確保都沒有不同就沒問題了。
在這邊補充一些如果python上有灌一堆版本,如: 透過brew ,官網,Anaconda,.....
在正式重新安裝時先把東西殺一殺:
- 官網的安裝了就安裝了,不用動
- anaconda 我是把它都殺掉因為其實我都沒用到它的安裝包,免得來亂
- 再來就是brew的部分,先把他殺掉。 因為教學的安裝路徑是以brew為主
- 可以先確認python安裝位置:
python
which python
一定要是:
python
usr/local/bin/python
如果不是,依照下面步驟:把他弄乾淨:
1.先在 ~/.bash_profile 裡面增加brew安裝路徑: https://gist.github.com/patriciogonzalezvivo/77da993b14a48753efda
export PATH=/usr/local/bin:$PATH
2.再到終端機:
\( brew uninstall --force python
\) brew install python
\( brew link --overwrite python
\) brew linkapps python
\( pip install --upgrade pip setuptools
\) sudo pip uninstall virtualenv
\( pip install virtualenv
\) sudo pip uninstall virtualenvwrapper
$ pip install virtualenvwrapper
3.再用which python確認位置是否正確,都沒錯就可以依照網頁教學正常安裝。http://www.pyimagesearch.com/2016/11/28/macos-install-opencv-3-and-python-2-7/
測試code: (先把安裝好後的環境引入pycharm再測試)
import cv2
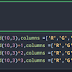
image = cv2.imread("123.png")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Original", gray)
cv2.waitKey(0)
The perfect computer vision environment: PyCharm, OpenCV, and Python virtual environments :
http://www.pyimagesearch.com/2015/08/17/the-perfect-computer-vision-environment-pycharm-opencv-and-python-virtual-environments/