資料的刪除基本上都是和網路上大家提到的方法一樣, 都是用drop的方式
但是我到的問題是:
假設我今天是有一堆數據依序讀出來然後存成了packle檔,(之後會再補上完整程式碼)
但是我必須要刪掉其中一行的數據,該怎辦?
假設我今天是有一堆數據依序讀出來然後存成了packle檔,(之後會再補上完整程式碼)
但是我必須要刪掉其中一行的數據,該怎辦?
一般是直接刪掉沒問題,但是我因為行沒有命名,主要是因為我存了一堆數據沒有必要去餵牠們命名,他們就只是我要做資料分析的訊號數據而已,如:

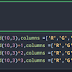
當刪除第2行的時候,之後就會變成 0 ,1,3 這並不是我要的
查了文檔發現並沒有針對columns做重新default的設定 只有index
查了文檔發現並沒有針對columns做重新default的設定 只有index
所以我換了方向,只好先將原本的dataframe做轉置,然後再利用set_index的方式把 0,1,3變成 0,1,2

只是記得要再轉置回來

原始碼:
import pandas as pdimport numpy as npd = pd.DataFrame(np.random.rand(3,4)*10)dr=d.Trr =r.drop([1],axis= 0)rrrrr =rr.reset_index(drop= True)# drop= true will reset the index order as default rrrrrr.Trrr.iloc[2]| 這封郵件來自 Evernote。Evernote 是您專屬的工作空間,免費下載 Evernote |





0 意見:
張貼留言